


触媒インフォマティクス
触媒インフォマティクスとは?
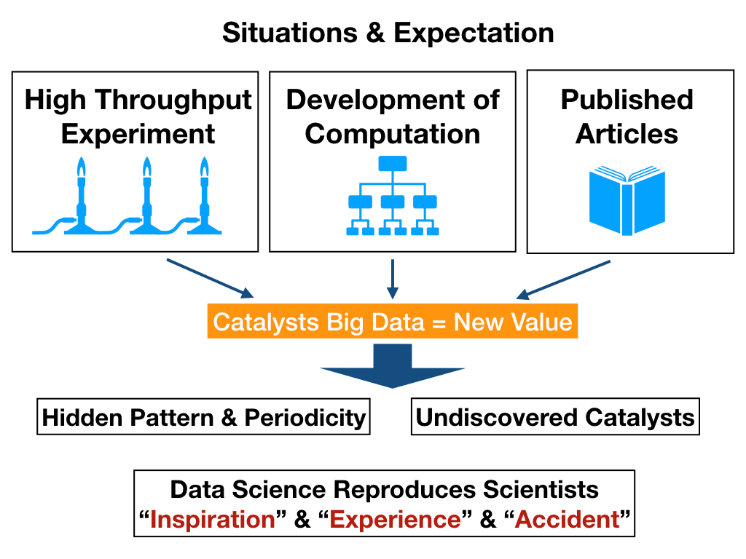
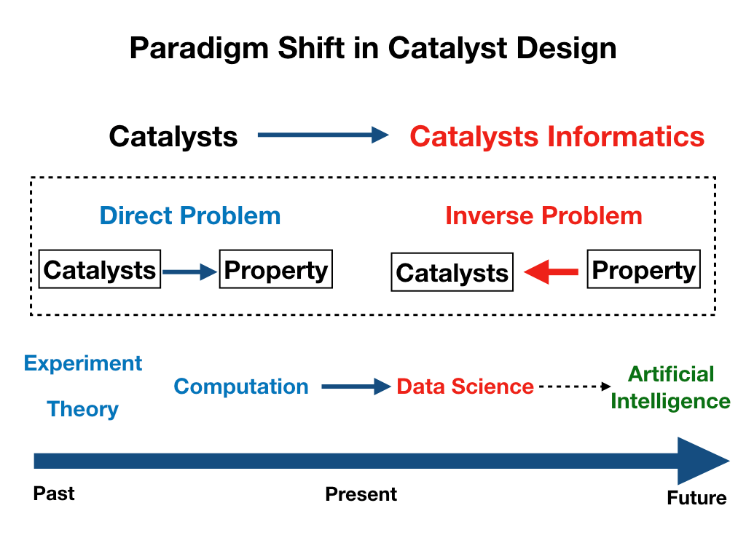
触媒インフォマティクスの具体的な動きが 2010 年頃より米国を中心始まった。2012 年には論文「The Catalyst Genome」(触媒ゲノム)が発表され触媒インフォマティクスが始動した。触媒ゲノムの意図するところはバイオインフォマティクスが成功したように,触媒の中にも生物のゲノム配列のような触媒効果を決定する遺伝子 ・パターンが存在し得るという期待が込められたものと考える。既に米国では「CatApp」という固体触媒上での炭素,水素,酸素を中心とするガス種の反応熱と活性化エネルギーを第一原理計算により算出しデータベース化し,一般公開している。このような流れの中,日本でも 2015 年よりマテリアルズインフォマティクスが立ち上がり,データ科学を主体とした材料開発が開始した。やはりデータ科学に求められるところは希望する反応を達成しうる触媒を提案するという逆問題に真意がある。このような X サイエンスから X インフォマティクスの動きはバイオロジーがバイオインフォマティクスに代表されるように,ケミストリー,マテリアルにも派生をし,触媒が触媒インフォマティクスに変貌するのも自然な流れと考える。
このような状況の中,触媒インフォマティクスを構成する重要要素とそのワークフローを示した。触媒インフォマティクスでは(1)触媒データ,(2)データ科学を用いた触媒データから知識への変換,(3)その 2 つを統合す るプラットフォームの 3 つの要素が相乗的に融合した時に成り立つ分野と考える
触媒イオンフォマティクスを構成する重要要素
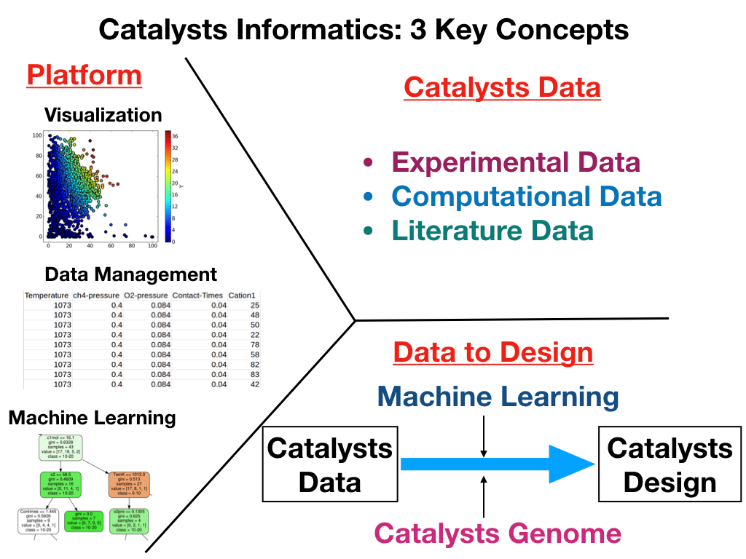
(1)触媒データ
触媒データは大きく分けて実験,計算,文献の 3 つの異なる特徴を持ったデータに分類することができる。実験データは現実的な触媒組成・触媒反応を再現しているだけでなく,実験プロセス条件も含まれている。その一方,実験データは作成に非常に時間が掛かるだけでなく,実験装置,時代,人によってデータの一貫性に問題が生じる。それに対して,計算データは比較的短時間にデータを収集することができ,ある程度のデータの一貫性を得られることができる一方,実験プロセス条件の欠如や非現実的な仮想触媒が得られてしまうことがある。最後は文献データである。 文献データは過去の触媒研究のデータを集めたもので,レビュー論文にまとめられているものを筆頭に多くの触媒データが文献という形で存在している。しかし過去の文献を調べると触媒データに大きな偏りがあることがわかる。特にメタン酸化カップリング反応の分野では触媒反応が突出した触媒が発見されると,その触媒を中心とし部分的に変化を加えた触媒などに集中していることがデータに見られ,データの偏りの原因になっていると考えられる。さらに触媒反応装置や触媒評価方法にも微妙な違いがあるため,同元素の触媒でも収率に違いが出てくるなどの問題も見受けられる。このようなデータに対してデータ科学を取り入れた場合,予測に大きな影響を及ぼすことが考えられる。さらに触媒データを新たに作成する場合においても,データの項目の設定や単位の統一も必要となってくる。このようなデータの偏り・不統一を防ぎ,触媒データを作成する上での共通ルールが必須となる。この問題を解決する方法としてオントロジーが有効と考える. 。オントロジーとは用語や概念など明確化し定義することにある。触媒データにおける用語・概念・単位などを明確に定義することにより統一された触媒データベース構築が可能となりえる。以上のように触媒科学では実験・計算・文献と異なる特徴を持つ 3 つのデータが存在するため,目的によって使い分けていくことが重要と考えると同時に,触媒インフォマティクス発展のためには触媒データベースにおける共通のルール作りが重要となる。
(2)データ科学
近年の機械学習ブームはディープラーニング(深層学習)による貢献が非常に大きい。特に顔認識や AlphaGo がプロの囲碁棋士に勝利するなど従来の機械学習とは一線を画すものである。ところがディープラーニングでは少なくとも 1 万から 100 万のデータが必要と言われている。ディープラーニングを触媒科学に適用しようとした場合,現在の触媒データではデータ数が圧倒的に少ないため対応することができない。そのような少ないデータに対応できるのが機械 学習である。ディープラーニングと機械学習の大きな違いは 2 つある。1 つはデータ数である。ディープラーニングでは数万のデータが最低必要であるが,機械学習では数百のデータで対応することができる。2 つ目は特徴量の抽出であ る。ディープラーニングでは自動でデータから特徴量を抽出するが,機械学習においては人間が特徴量を選定し機械に教えなければならない。そのため機械学習導入時の課題は触媒反応を決定する特徴量をどのように定義・抽出するかが 鍵となる。また機械学習には単純な線形回帰を筆頭に,サポートベクターマシン,ランダムフォレストなど数多くの機械学習手法が存在する。そのため触媒データに対して適切な機械学習機,そして特徴量の選出の両方を同時に行わなけ ればならない。触媒インフォマティクスの草創期においては,触媒データの解析,機械学習機の選定,特徴量の抽出などそれら一連の流れを探索すること自体が最重要研究対象となると考える。
(3)触媒インフォマティクス統合プラットフォーム
触媒インフォマティクスは触媒データの収集から始まり,データ科学を用いた触媒予測までを一気に担い,分野を超えた領域である。そのためデータベース構築・管理,データ解析,データ可視化,機械学習と幅広い情報技術と触媒の知識が要求される。これらの技術は独立して存在しているため,触媒インフォマティクス発展のためには,これらの技術を統合し,誰もが難しいプログラミング技術を必要としなくても触媒データから触媒開発が可能となるプラット フォームが重要な鍵となる。同時に触媒データが存在してこその触媒インフォマティクスであるため,プラットフォームではデータベースを簡易に公開・管理・運用ができることが必須であり,触媒データの源泉となる必要がある。
触媒インフォマティクスはマテリアルズインフォマティクスとは一線を画す最難関のインフォマティクスといっても過言ではない。触媒科学は組成の探索だけでは触媒反応を評価・予測することは難しく,実験プロセス条件の寄与が大きい。直接的な触媒反応場においても構造の変化や複雑な反応が随時進行していると考えられ,生物のようである。そのため触媒組成に束縛されず,実験プロセス条件も特徴量として考慮していく必要があり,触媒実験とデータ科学が綿密に連携し,触媒インフォマティクスを発展させていかなければならない。
ⒸTakahashi, et. al The Rise of Catalyst Informatics: Towards Catalyst Genomics. ChemCatChem. (2019) doi:10.1002/cctc.201801956
研究概要
本研究では実験・計算・データ科学を統合したキャタリストインフォマティクスを推進し、新しい革新的な触媒探索・反応機構解明技術を創出することを目的とし以下の2点の達成に重点を置きます。
- 新規触媒の発見・実験プロセスの最適化による触媒性能向上
- 触媒反応機構解明・制御
特にメタン変換プロセスを対象とし新しいメタン変換触媒・最適プロセス・反応経路機構の完全解明・制御を実現し、新しいメタン変換プロセスを提案します。
本研究は以下の3本柱を軸に遂行します。
- 実験・計算・文献からなる触媒データベースの構築
- 機械学習を用いた触媒データから知識への変換
- 触媒探索・設計統合プラットフォーム開発
本研究により実験・計算・データ科学が融合した一連の道筋を実証し、‟X”学から‟X”インフォマティクスの革命を触媒で起こすことを提案します。
本研究を達成するため以下の4チームを編成しました。
ハイスループット計算・データ科学グループ(髙橋グループ)
- 完全自動化ハイスループット計算システムの開発
- 機械学習による触媒予測
- 触媒探索・設計統合プラットフォーム開発
データ科学・反応経路グループ(宇野グループ)
- GRRMを用いたメタンの反応経路マップ構築
- 経路列挙アルゴリズムの技術を用いた触媒反応機構解明
触媒開発・解析グループ(大山グループ)
- 予測された触媒開発
- 各種物理化学的手法を用いた触媒解析(組成・構造)
ハイスループット実験グループ(谷池グループ)
- ハイスループット触媒評価システムの開発(20触媒 x 20プロセス条件/日)
- 多変量解析によるデータ可視化